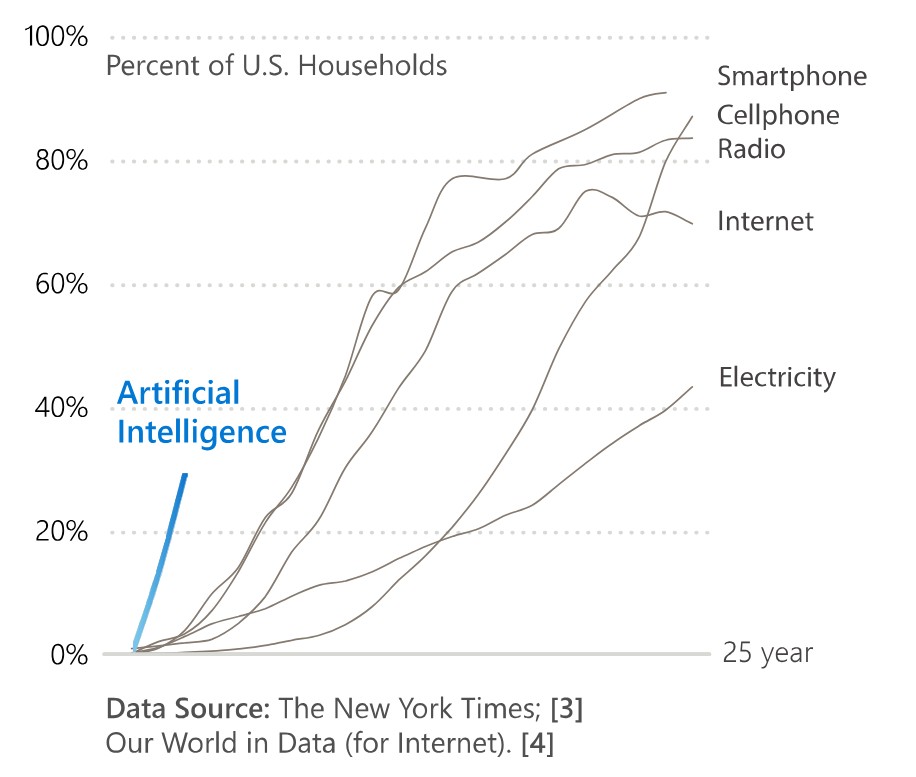
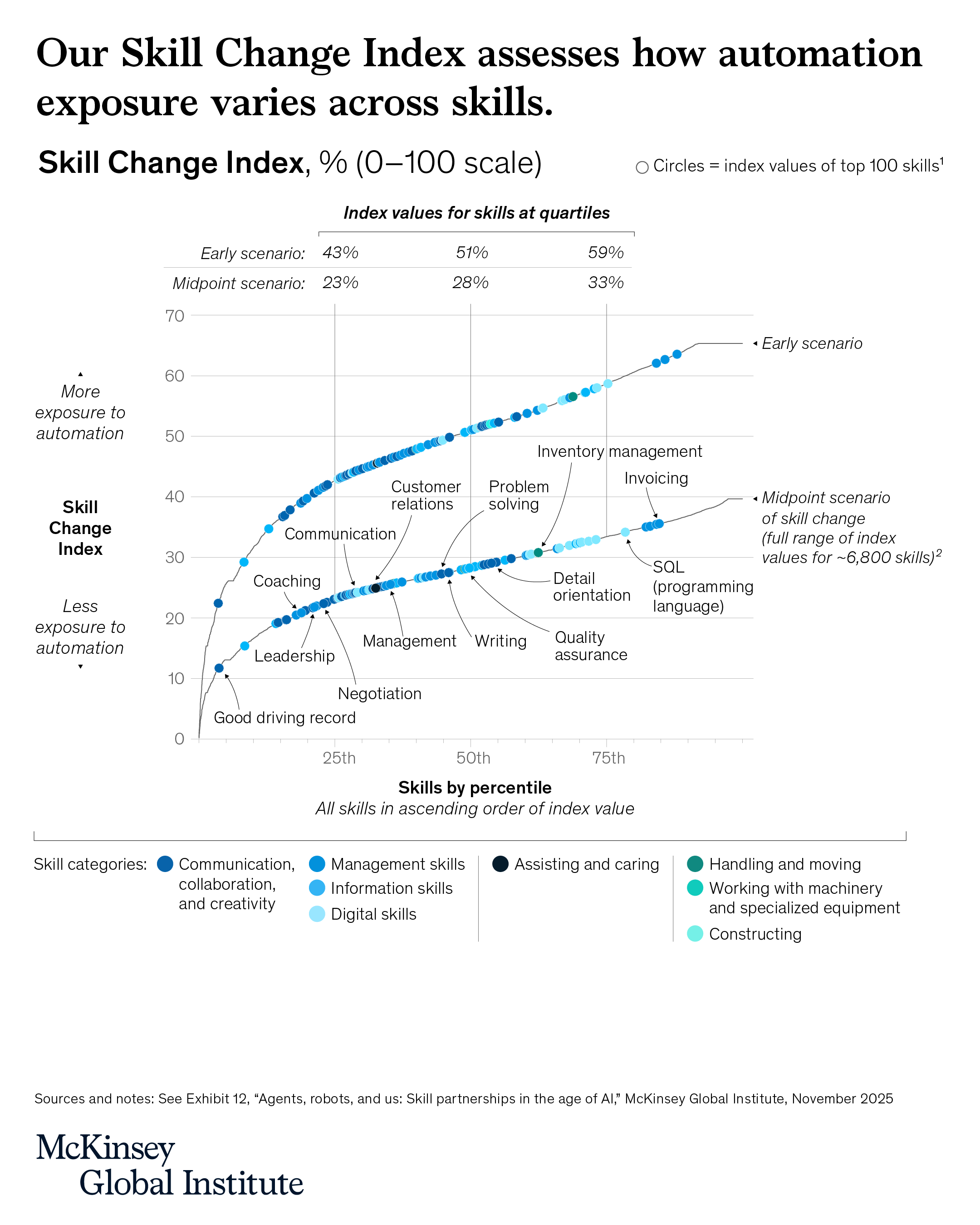
Gartner: top IT strategic predictions for 2026 and beyond
- Through 2027, gen AI and AI agent use will create the first true challenge to mainstream productivity tools in 30 years, prompting a $58 billion market shakeup.
- By 2027, 75% of hiring processes will include certifications and testing for workplace AI proficiency during recruiting
- Through 2026, atrophy of critical-thinking skills, due to gen AI use, will push 50% of the global organizations to require “AI-free” skills assessments.
- By 2027, 35% of countries will be locked into region-specific AI platforms using proprietary contextual data.
- By 2028, organizations that leverage multi-agent AI for 80% of customer-facing business processes will dominate.
- By 2028, 90% of B2B buying will be AI agent intermediated, pushing over $15 trillion of B2B spend through AI agent exchanges.
- By the end of 2026, “death by AI” legal claims will exceed 2,000 due to the insufficient implementation of AI risk guardrails.
- By 2030, 20% of monetary transactions will be programmable to include terms and conditions of use, to give AI agents economic agency.
- By 2027, the cost-to-value gap for process-centric service contracts will be reduced by at least 50% due to agentic AI reinvention.
- By 2027, fragmented AI regulation will grow to cover 50% of the world’s economies, driving $5 billion in compliance investment.
Source: