December 17, 2025
December 17, 2025
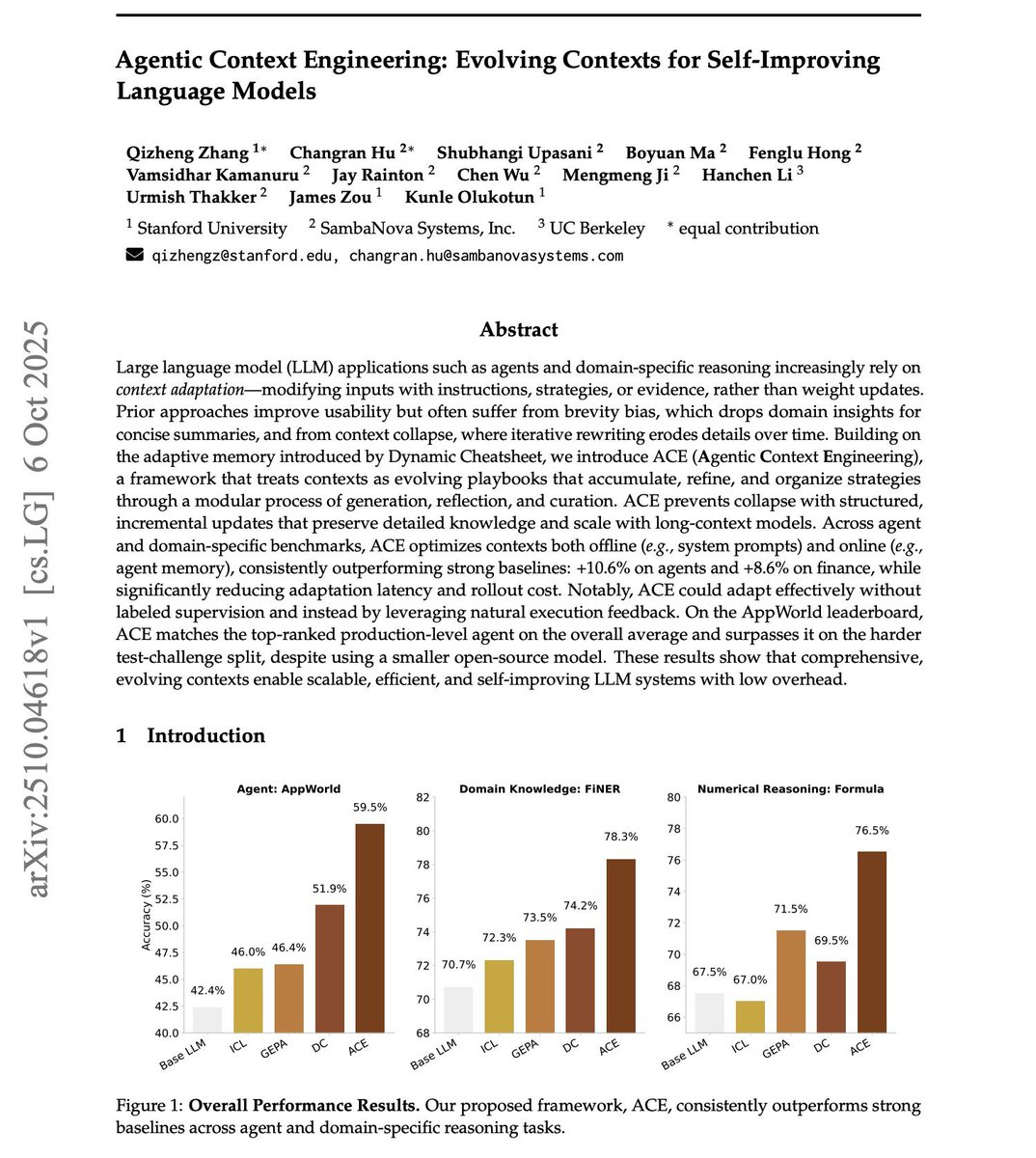
Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation—modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead
December 17, 2025
Stanford berhasil membuat hacker berbasis Artificial Intelligence bernama ARTEMIS. Software hacker ini berhasil membobol sebagian aplikasi di jaringannya.

Sumber:
#
December 17, 2025
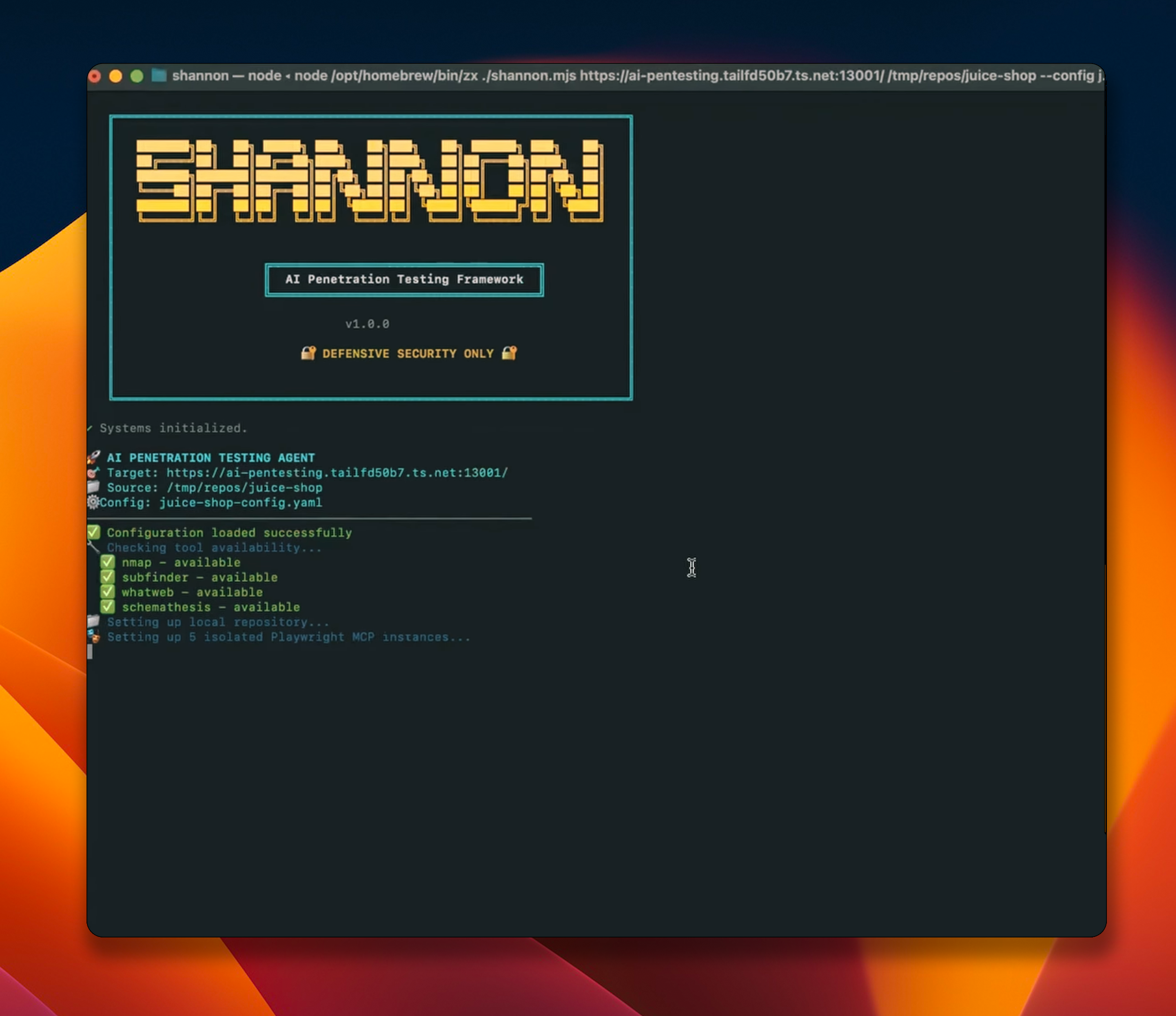
Shannon adalah perangkat lunak pentester berbasis Artificial Intelligence.
Fitur utama:
- Beroperasi secara otonom, tidak perlu manual
- Laporan pentester dengan exploit yang dapat direproduksi
- Critical OWASP Vulnerability Coverage
- Code-Aware Dynamic Testing
- Powered by Integrated Security Tools
- Parallel Processing for Faster Results
Sumber:
#
December 17, 2025
Vulnerable API adalah contoh software yang di dalamnya berisi vulnerability OWASP top 10.
Sumber:
#
December 16, 2025
The rise of AI agents is transforming how software can be built. The promise of agents is that developers might write code quicker, delegate multiple tasks to different agents, and even write a full piece of software purely out of natural language. In reality, what roles agents play in professional software development remains in question. This paper investigates how experienced developers use agents in building software, including their motivations, strategies, task suitability, and sentiments. Through field observations (N=13) and qualitative surveys (N=99), we find that while experienced developers value agents as a productivity boost, they retain their agency in software design and implementation out of insistence on fundamental software quality attributes, employing strategies for controlling agent behavior leveraging their expertise. In addition, experienced developers feel overall positive about incorporating agents into software development given their confidence in complementing the agents’ limitations. Our results shed light on the value of software development best practices in effective use of agents, suggest the kinds of tasks for which agents may be suitable, and point towards future opportunities for better agentic interfaces and agentic use guidelines.
December 5, 2025
December 5, 2025
Beberapa model AI LLM open:
- Writing: Kimi k2 / Thinking
- Coding: Minimax M2 / GLM 4.6
- OCR: DeepSeek / Qwen 3 VL
- General: DeepSeek V3.2
- Image: Flux 2 Dev / Z-Image
- Reasoning : DeepSeek v3.2 speciale
Metode akses:
- Writing : Official Chat UI Kimi
- Coding : Zed / KiloCode
- OCR : Official Chat / via API
- General : Official Chat Deepsek
- Reasoning : Official / via API
- Image Editing dan Image : hugging face, ModelScope
December 1, 2025
Students use AI to write papers, professors use AI to grade them, degrees become meaningless, and tech companies make fortunes. Welcome to the death of higher education. Ronald Purser
Source:
November 27, 2025

Stanford researchers built a new prompting technique!
By adding ~20 words to a prompt, it:
- boosts LLM’s creativity by 1.6-2x
- raises human-rated diversity by 25.7%
- beats fine-tuned model without any retraining
- restores 66.8% of LLM’s lost creativity after alignment
Post-training alignment methods, such as RLHF, are designed to make LLMs helpful and safe.
However, these methods unintentionally cause a significant drop in output diversity (called mode collapse).
November 25, 2025
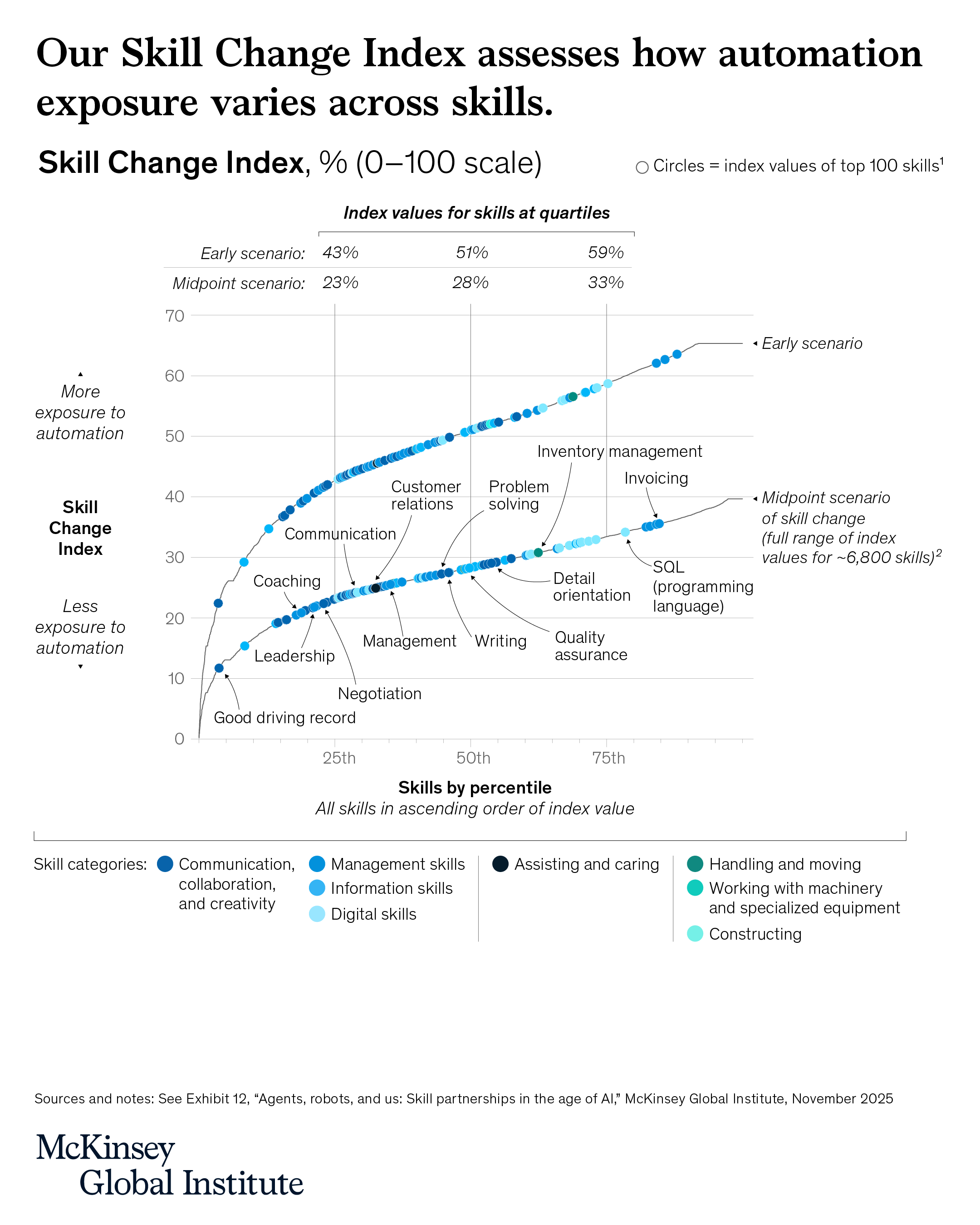
AI is expanding the productivity frontier. Realizing its benefits requires new skills and rethinking how people work together with intelligent machines.
At a glance
#
- Work in the future will be a partnership between people, agents, and robots—all powered by AI. Today’s technologies could theoretically automate more than half of current US work hours. This reflects how profoundly work may change, but it is not a forecast of job losses. Adoption will take time. As it unfolds, some roles will shrink, others grow or shift, while new ones emerge—with work increasingly centered on collaboration between humans and intelligent machines.
- Most human skills will endure, though they will be applied differently. More than 70 percent of the skills sought by employers today are used in both automatable and non-automatable work. This overlap means most skills remain relevant, but how and where they are used will evolve.
- Our new Skill Change Index shows which skills will be most and least exposed to automation in the next five years. Digital and information-processing skills could be most affected; those related to assisting and caring are likely to change the least.
- Demand for AI fluency—the ability to use and manage AI tools—has grown sevenfold in two years, faster than for any other skill in US job postings. The surge is visible across industries and likely marks the beginning of much bigger changes ahead.
- By 2030, about $2.9 trillion of economic value could be unlocked in the United States—if organizations prepare their people and redesign workflows, rather than individual tasks, around people, agents, and robots working together.